在过去的数月中,亚马逊云科技已经推出了多篇介绍如何在亚马逊云科技上部署Stable Diffusion,或是如何结合Amazon SageMaker与Stable Diffusion进行模型训练和推理任务的内容。
为了帮助客户快速、安全地在亚马逊云科技上构建、部署和管理应用程序,众多合作伙伴与亚马逊云科技紧密合作。他们提供各种各样的服务、深入的技术知识、最佳实践和解决方案,包括基础设施迁移、应用程序现代化、安全和合规性、数据分析、机器学习、人工智能、云托管、DevOps、咨询和培训。
最近,亚马逊云科技核心级服务合作伙伴eCloudrover(伊克罗德)推出了基于Stable Diffusion的AI绘画解决方案——imAgine,既拥有经过广泛验证且易于部署的先进AI算法模型,又提供丰富且高性价比的云端资源以优化成本,旨在帮助游戏、电商、媒体、影视、广告、传媒等行业快速构建AIGC应用通路,打造AI时代的领先生产力。
Stable Diffusion实战技巧
古语有云:“万事开头难”,“致广大而尽精微”。这对应了在Stable Diffusion实战中,客户最常遇到的两方面问题,一是如何选择合适的提示词起手式,来生成满足期望的图片;二是如何对图片进行细节优化,使最终产出的结果能够满足生产应用需求。
根据过往服务客户使用Stable Diffusion的经验,整理了以下内容作为推荐的最佳实践,希望对读者使用Stable Diffusion进行创作时提供参考。
提示词工程
随着Stable Diffusion版本不断迭代,AI对语义的理解越来越接近“常识”之后,对提示词(Prompts)的要求也会越来越高。很多提示词上的误区有时会对绘图产生反作用。
Prompt的基本概念
提示词分为正向提示词(positive prompt)和反向提示词(negative prompt),用来告诉AI哪些需要,哪些不需要。
Prompt的误区
Prompt在于精确,不在于数量;用最简短的单词阐述画面,比自然语言要更有效。
提升质量的描绘词绝不是无脑堆砌、越多越好。
经常出现的起手式:“masterpiece”“best quality”等,很多时候会成为提示词中的累赘。这些词语在NovelAI时代是有意义的,因为当时NovelAI训练模型时大量使用了这些词汇来对图像进行评价;但在如今,经过Civitai上模型作者们不断重新炼制模型,这些提示词已经很难在生图结果中展现应有的作用。
调整提示词的权重
词缀的权重默认值都是1,从左到右依次减弱
提示词权重会显著影响画面生成结果
通过小括号+冒号+数字来指定提示词权重,写法如(one girl:1.5)
注意提示词的顺序
比如景色Tag在前,人物就会小,相反的人物会变大或半身
选择正确的顺序、语法来使用提示词,将更好、更快、更有效率地展现所想所愿的画面
Prompt中的Emoji
Prompt支持使用emoji,且表现力较好,对于特定的人脸表情或动作,可通过添加emoji图来达到效果
为了防止语义偏移,优先考虑emoji,然后少用不必要的with一类的复杂语法
视角Prompt推荐
参数解释
extreme closeup脸部特写
close up头部
medium close up证件照
medium shot半身
cowboy shot无腿
medium full shot无脚
full shot全身
图片优化
很多时候我们生成了一张差强人意的图片,希望对这个结果进行进一步的优化,但往往不知道从何下手。这时您或许可以参考以下图片参数调优的最佳实践:
哪些参数需要调整
CFG Scale:图像与提示词的相关度。该值越高,提示词对最终生成结果的影响越大,契合度越高。
CFG 2-6:有创意,但可能太扭曲,没有遵循提示。对于简短的提示来说,可以很有趣和有用。
CFG 7-10:推荐用于大多数提示。创造力和引导力度之间的良好平衡。
CFG 10-15:当您确定提示是详细且非常清晰的,对图片内容有极明确的要求时使用。
CFG 16-20:除非提示非常详细,否则通常不推荐。可能影响一致性和质量。
CFG >20:几乎无法使用。
Sampling Steps迭代步数:步骤越多,每一步图像的调整也就越小、越精确。同时也会成比例地增加生成图像所需要的时间。
对于大部分采样器,迭代越多次效果越好,但超过50步后就收效甚微。
Sampling method采样方法:不同的采样方法,对应的最佳迭代步数是不同的,在进行对比时需要综合考虑。
Euler a:富有创造力,不同步数可以生产出不同的图片。并且这是一个效率较高的采样方法,可以用来快速检查prompt效果的好坏。
DPM2 a Karras:适合跑真实模型,30步以后不好把控。
DPM++ 2M Karras:在高步数下表现优异,步数越高细节越多。
DDIM:收敛快,但效率相对较低,因为需要很多step才能获得好的结果,适合在重绘时候使用。
不同模型与采样方法搭配出的结果也不同,以上仅供参考,在进行采样方法的选择时,最好使用X/Y/Z图表进行对比。
Seed随机种子:随机种子值很多时候对构图的影响是巨大的,这也是SD生图随机性的最主要来源。
保持种子不变,同样的提示词和模型,保持所有参数一致的情况下,相同的种子可以多次生成(几乎)相同的图像。
在确定好一个合适的画面构图时,固定种子,对细节进行进一步打磨,是最合适的做法。
如何对比寻找最佳参数
利用X/Y/Z图找最佳参数:通过使用X/Y/Z图,我们可以很清晰地对比不同参数下的结果,快速定位合适的参数范围,进行进一步的生成控制。
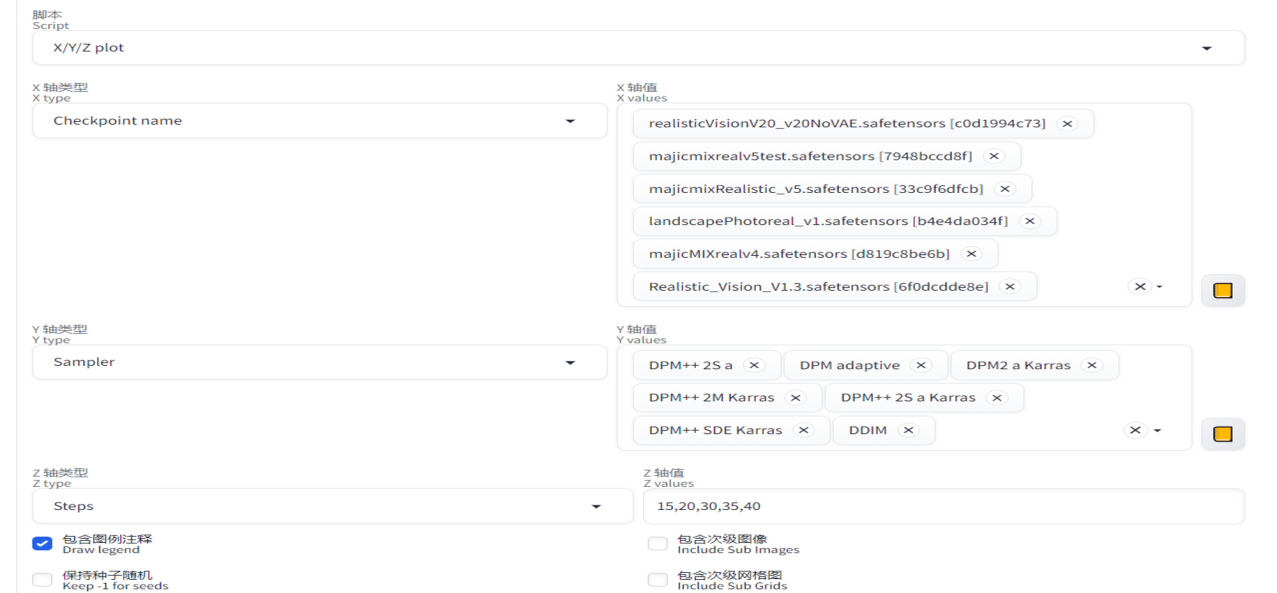
图片尺寸优化
图片质量并不直接与图像尺寸挂钩。
但尺寸在一定程度上影响了主题/图片内容,因为它潜在代表选择的类别(比如竖屏人物,横屏风景,小分辨率表情包等)。
当出图尺寸太宽时,图中可能会出现多个主体。
1024之上的尺寸可能会出现不理想的结果,并且对服务器显存压力是巨大的。推荐使用小尺寸分辨率+高清修复。
优化多人物/宽幅单人物的生成
单纯使用txt2img无法有效指定多人物情况下,单个人物的特征。
较为推荐的方案是制作草稿+img2img或ControlNet的方式。
宽幅画作+单人物生成最好打草图,进行色彩涂抹,确定画面主体;或使用ControlNet的OpenPose做好人物骨架。
多人物确定人物数量,最好使用ControlNet的OpenPose来指定;该方案也适合画同一人物的三视图。
进行手部修复
将图片送入img2img inpaint,使用大致相同的提示词,将关于“手”的提示放在前面,根据希望手部特征变动多少来设置重绘幅度(如果只是希望手更完整,调至0.25以下),然后保留步骤和CFG与txt2img相同。
找到一个满足期望的手部图片,借助ControlNet的Canny或OpenPose_hands等预处理器+模型,结合inpaint操作,能实现更精确的手部控制。
进行面部修复
在绘制人物主体较小的图片时,经常会出现面部崩坏的情况。尤其是本文之后会介绍的生成艺术二维码流程,人物的面部经常会因为二维码码点的存在而崩坏。
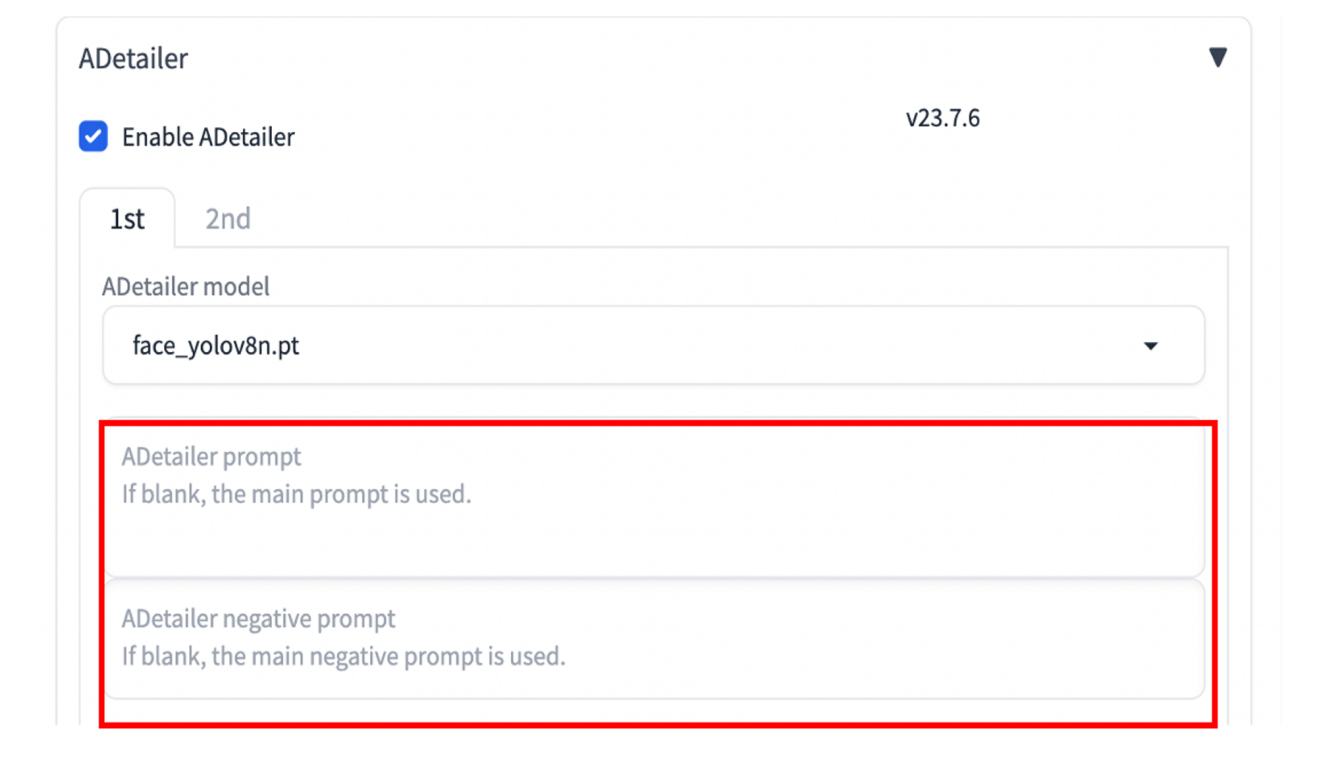
对面部的重绘,更推荐使用!After Detailer插件实现,通称ADetailer。
该插件会使用yolo算法对图片中的物体进行识别,我们设定其识别人物面部,并提供面部重绘的提示词和模型;该插件会在识别到的面部位置进行局部重绘,完成面部修复。
ADetailer插件可以满足面部和手部的识别与修复。
在ADetailer中也能引用Lora模型进行局部重绘生成。
原标题:借助 ControlNet生成艺术二维码——基于Stable Diffusion的AI绘画方案
原链接:https://aws.amazon.com/cn/blogs/china/art-qr-code-generation-with-controlnet-ai-painting-solution-based-on-stable-diffusion/